
EN
在處理PDF、掃描件等文檔時,簡單的復(fù)制粘貼或傳統(tǒng)OCR常常導(dǎo)致版面錯亂、閱讀順序顛倒、表格數(shù)據(jù)破碎。尤其面對復(fù)雜的圖文混排、多欄布局時,如何才能精準(zhǔn)地“讀懂”并還原文檔原始結(jié)構(gòu)?
易道博識智能文檔比對系統(tǒng)通過全面識別文檔元素,并運(yùn)用算法智能還原圖文混排、多欄布局及跨頁表格的原始結(jié)構(gòu)與閱讀順序,實現(xiàn)版面的精準(zhǔn)重構(gòu)。
系統(tǒng)首先對上傳的文檔進(jìn)行深度分析,無論其格式是PDF、JPG還是Word。它能夠精準(zhǔn)識別并分類文檔中的標(biāo)題、段落、表格、圖片、印章、公式等十余種核心元素。經(jīng)驗表明,高精度的元素識別是保證后續(xù)版面還原準(zhǔn)確性的首要前提,尤其是對于金融研報、合同等格式不一的文檔至關(guān)重要。
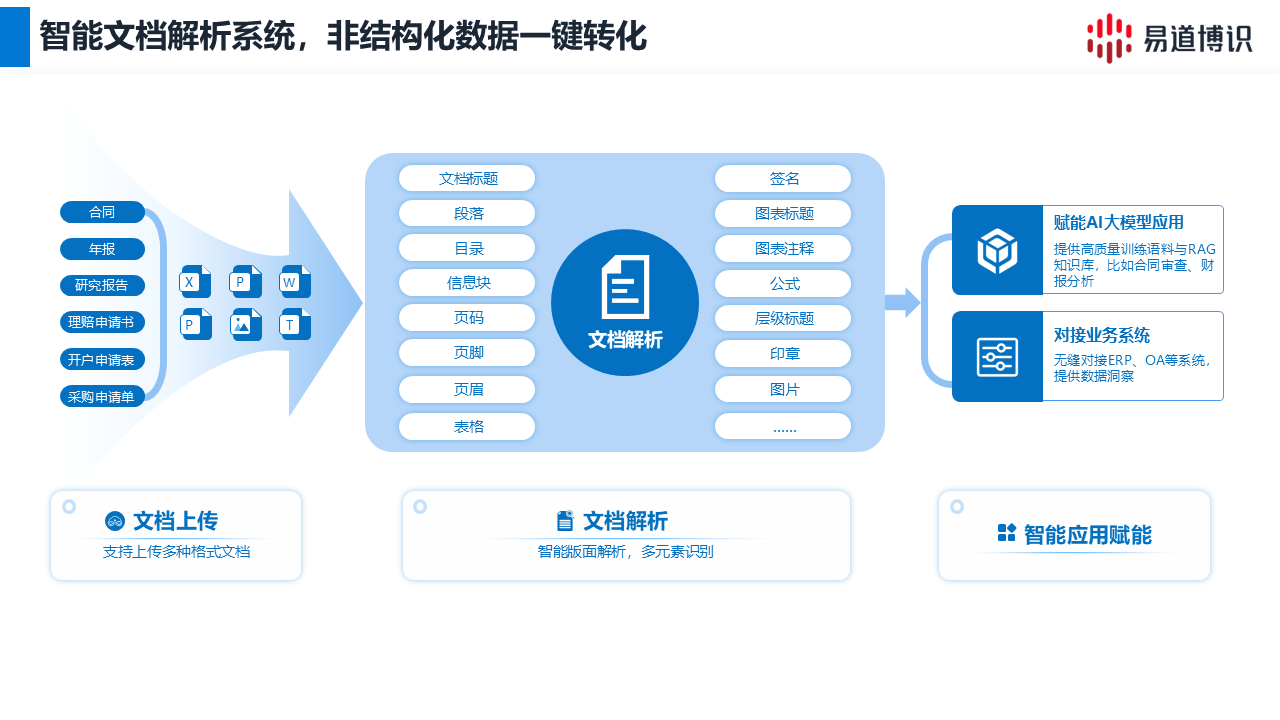
在處理如研究報告、技術(shù)手冊這類圖文混排文檔時,系統(tǒng)并非簡單地按物理位置提取文字。它會智能分析圖文區(qū)域的邏輯關(guān)系,判斷圖片標(biāo)題與圖片的對應(yīng)關(guān)系,以及文字與插圖之間的上下文聯(lián)系,從而還原出符合人類閱讀習(xí)慣的正確順序。
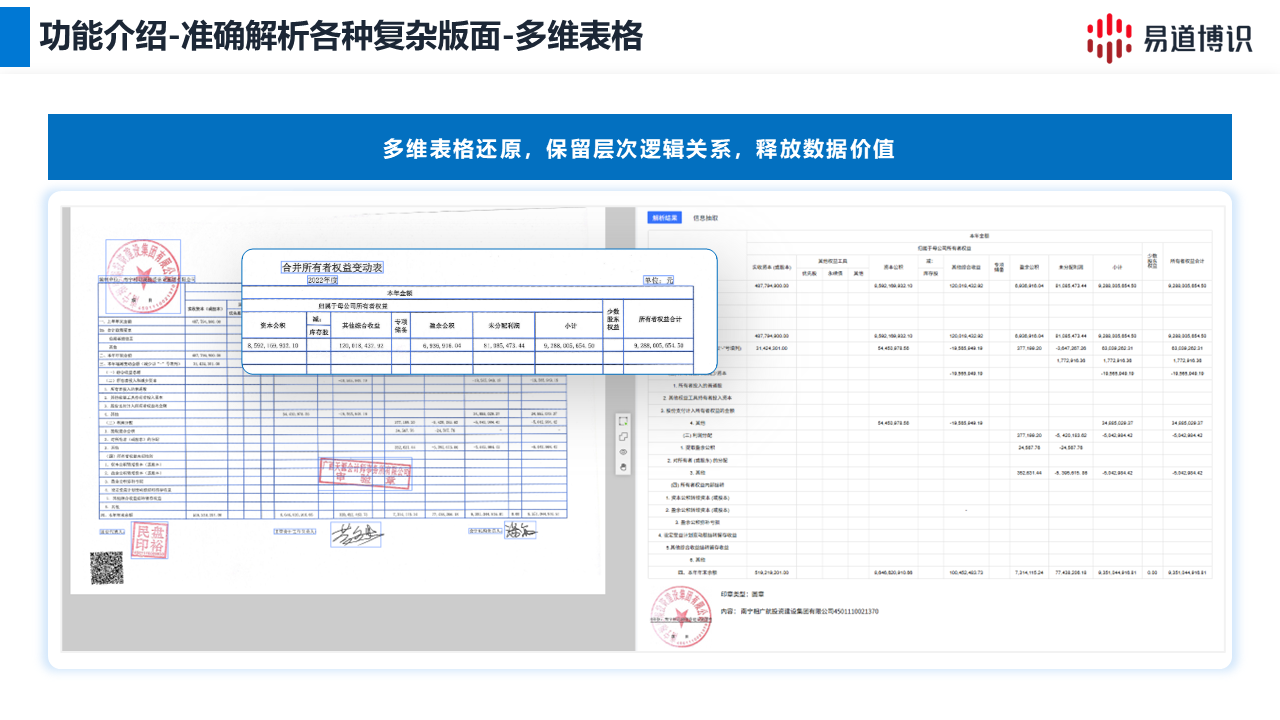
對于跨頁表格,系統(tǒng)具備自動檢測和拼接能力。它能識別出上百頁年報中跨頁表格的連續(xù)部分,并將其還原為一個邏輯完整的統(tǒng)一數(shù)據(jù)表,極大簡化了財務(wù)報表等文檔的數(shù)據(jù)處理。 對于多維復(fù)雜表格(如多級表頭、嵌套單元格),不僅能提取數(shù)據(jù),更能解析和保留數(shù)據(jù)間的層級與隸屬關(guān)系。
這意味著,一個復(fù)雜的財務(wù)報表可以被轉(zhuǎn)化為結(jié)構(gòu)清晰、帶有層級信息的數(shù)據(jù)格式,直接用于數(shù)據(jù)分析,真正釋放了表格中的數(shù)據(jù)價值。
版面還原的最終目的是激活數(shù)據(jù)價值。易道博識智能文檔比對系統(tǒng)提供了Markdown和JSON兩種核心輸出格式以滿足不同需求。
Markdown格式:最大程度保留原始版式和內(nèi)容結(jié)構(gòu),適合內(nèi)容歸檔和閱讀。
JSON格式:這是賦能下游系統(tǒng)的關(guān)鍵。它提供了每個文字、段落的精確坐標(biāo)位置,方便核查。
FAQ: 問題:易道博識智能文檔比對系統(tǒng)支持哪些文檔格式的解析?
回答:系統(tǒng)支持PDF、JPG、PNG、Word、Excel、PPT等多種主流格式的批量解析,具備卓越的格式兼容性。
問題:能否自定義提取文檔中的特定信息?
回答:可以。支持用戶通過簡單的提示詞自定義抽取規(guī)則,實現(xiàn)對任意版式文檔中關(guān)鍵字段的自動化提取。





