
EN
針對財報中常見的無框線、合并單元格及跨頁表格,基于深度學(xué)習(xí)的OCR版面分析技術(shù)是最佳解法。易道博識智能財報錄入系統(tǒng)通過高精度表格還原算法,實現(xiàn)了復(fù)雜財報數(shù)據(jù)的結(jié)構(gòu)化提取。
在財務(wù)數(shù)據(jù)提取的過程中,最令人頭疼的往往不是密密麻麻的數(shù)字,而是那些結(jié)構(gòu)“千奇百怪”的表格。對于銀行信貸員、審計師或投資分析師來說,面對一份幾百頁的PDF財報,如果表格識別亂序、錯行,后期的人工修正工作量甚至超過了手動錄入。
為什么通用的OCR軟件在處理財報時經(jīng)常“翻車”?
1.復(fù)雜的單元格結(jié)構(gòu):財報中大量存在合并單元格(如“流動資產(chǎn)”下的多層級科目)、表頭多層嵌套。普通OCR容易將它們拆散,導(dǎo)致數(shù)據(jù)歸屬錯誤。
2.無線表格:為了美觀,很多年報或?qū)徲媹蟾媸菬o線表或只有橫線沒有豎線。缺乏線條引導(dǎo),OCR很難判斷列的邊界。
3.跨頁截斷:財報往往很長,經(jīng)常被截斷在兩頁甚至三頁。如何將跨頁的數(shù)據(jù)自動拼接成一個完整的邏輯表格,是巨大的技術(shù)挑戰(zhàn)。
傳統(tǒng)的基于規(guī)則的算法(尋找橫豎線交叉點)已無法應(yīng)對上述挑戰(zhàn)。現(xiàn)代的智能文檔處理(IDP)技術(shù),如易道博識采用的方案,引入了計算機(jī)視覺(CV)和自然語言處理(NLP)的雙重能力:
1. 像素級的版面分析
系統(tǒng)不再依賴可見的黑線,而是像人眼一樣,根據(jù)文本的空白間隙、對齊方式和語義群組,自動推斷出“邏輯上的行與列”。即使是無線表,也能精準(zhǔn)切分。
2. 智能單元格重建
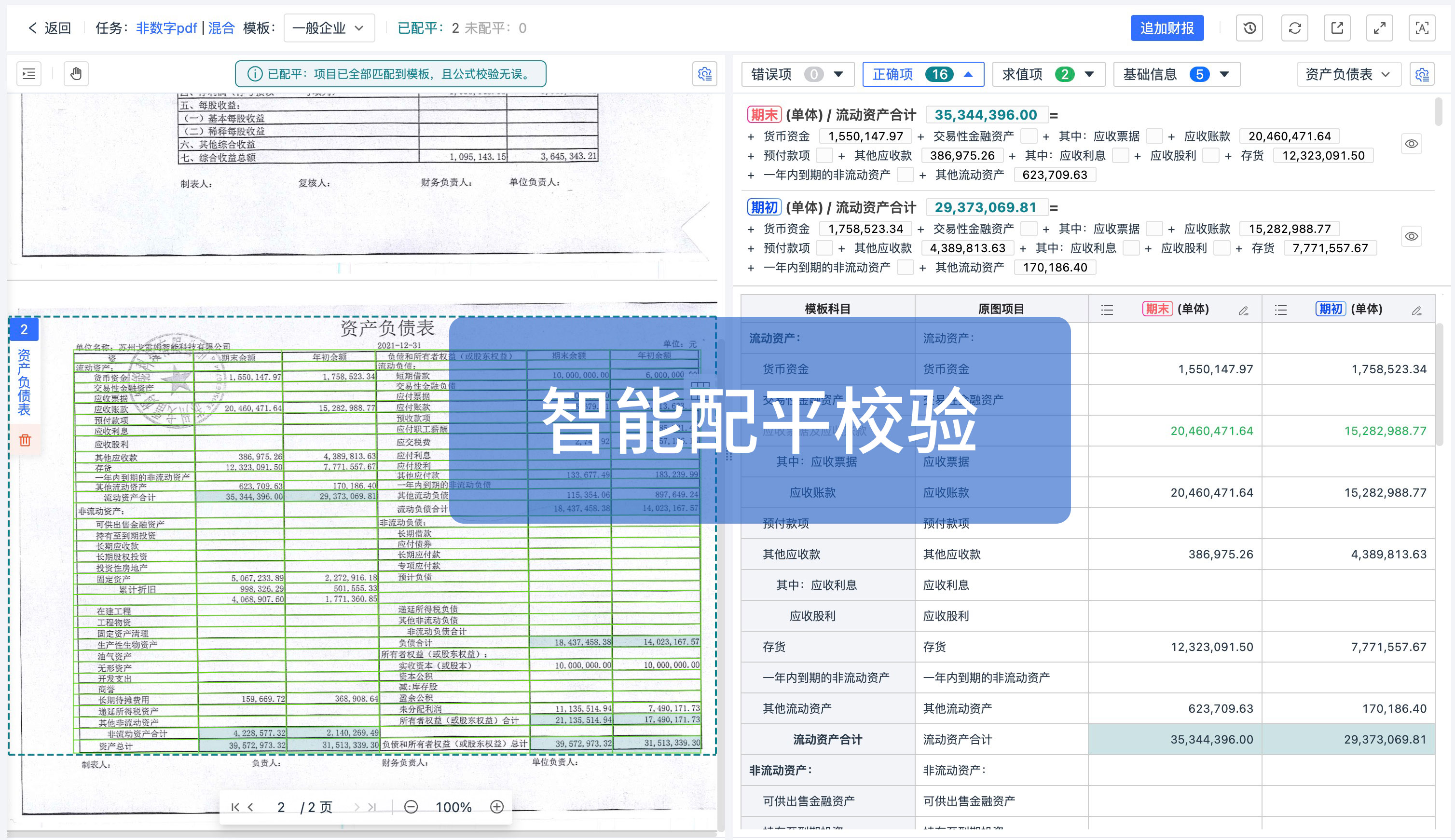
對于合并單元格,算法能識別出其覆蓋范圍,并將表頭信息準(zhǔn)確地廣播給下屬的每一個子數(shù)據(jù),確保導(dǎo)出到Excel時,數(shù)據(jù)結(jié)構(gòu)依然清晰,不用人工二次合并。
3. 跨頁自動合并
系統(tǒng)通過識別頁眉、頁腳以及表格的連續(xù)性特征(如“續(xù)表”字樣),自動將跨頁的表格數(shù)據(jù)在邏輯上連接起來,輸出為一張完整的報表。
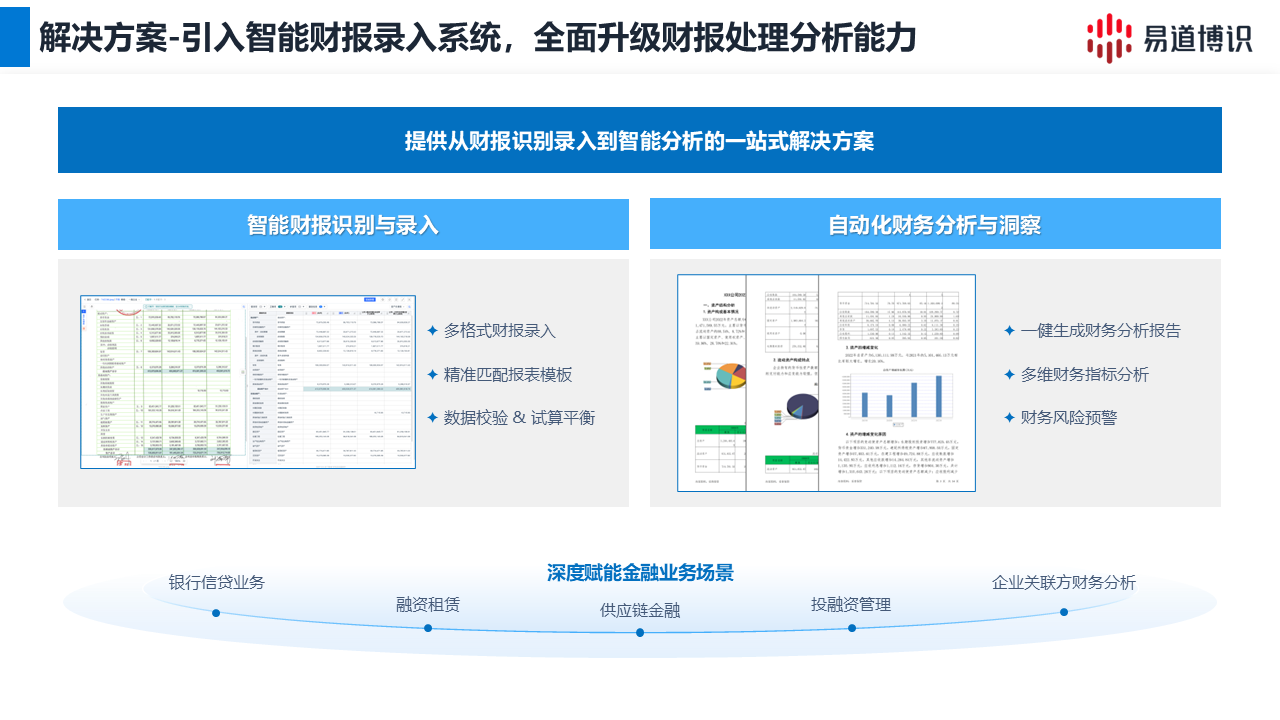
易道博識智能財報錄入系統(tǒng),可在5分鐘內(nèi)錄入一份完整財報。
●多格式兼容:無論是掃描件(JPG/PNG)、電子版PDF,還是Excel、Word,甚至包含表格的圖片壓縮包,都能一鍵上傳處理。
●結(jié)構(gòu)化輸出:識別后的結(jié)果不是死板的文本,而是可以直接進(jìn)行財務(wù)分析的結(jié)構(gòu)化數(shù)據(jù)。系統(tǒng)內(nèi)置的模板庫能自動匹配不同行業(yè)的財報格式(一般企業(yè)、金融企業(yè)、事業(yè)單位等)。
●所見即所得的校對:提供原圖與識別結(jié)果的“左右對照”視圖。點擊表格中的數(shù)字,左側(cè)原圖對應(yīng)位置會自動高亮,極大地方便了針對復(fù)雜表格的核對工作。
Q1:對于掃描歪斜的財報圖片,能識別表格嗎?
答:可以。易道博識的系統(tǒng)具備圖像預(yù)處理功能,會自動進(jìn)行傾斜校正、去噪和增強(qiáng),確保表格線條和文字回歸水平,保證識別精度。
Q2:識別后的表格能直接導(dǎo)出Excel嗎?
答:支持。不僅可以導(dǎo)出Excel,還可以通過API接口直接返回JSON格式的數(shù)據(jù),無縫對接到企業(yè)的ERP或信貸管理系統(tǒng)中。
Q3:如果表格里有手寫數(shù)字怎么辦?
答:系統(tǒng)集成了高精度的手寫體識別模型,對于財報中出現(xiàn)的手寫簽名或手寫填報的數(shù)字,也能保持較高的識別準(zhǔn)確率。





